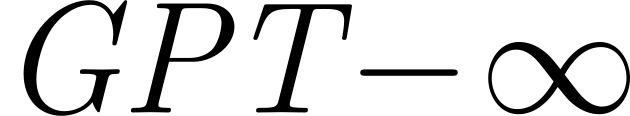Born: Summer 2012 Adopted: February, 2021 Died: May 8, 2026
JoJo was diagnosed with large cell lymphoma with the first symptoms showing up in July 2025. JoJo underwent surgery to remove a mass found on his small intestine, and went through the CHOP chemotherapy protocol to try to address any tumors that were not removed by the surgery. JoJo completed his cancer treatments in January 2026. However, symptoms of cancer returned within a month in February 2026. We choose to not resume chemotherapy, and keep JoJo as comfortable as possible for the remaining months of his life.
Eulogy
JoJo, you first came into Angela’s life during Covid in February of 2021. You were a senior cat that had been returned to the shelter due to circumstances with your first family, and so we were your second family. In your second family, you initially found both Angela and Professor Meatball.
When Angela first got you, you were a very large cat, and needed to go onto a diet. You would always attempt to steal food from others, including human food.
I first meet you, Professor Meatball and Angela in the summer of 2021. Within a few weeks of first meeting you, I ended up watching you for a week while Angela was away. During this time, I brought you over to my apartment for the week and you ended up meeting Patton. I remember the first interaction between the two of you. Patton was was a bit annoyed to have you there, however you did not seem to mind being a new place with a new cat that much after you settled down from being carried over. You were only interested in food and what food you could find. You truly were our stomach with legs.
During that first week, you were a friendly cat trying to be respectful of Patton and his home, while chronically looking around for food.
While your first visit visit with Patton only lasted a week, you did eventually move in with Angela, and become a lifelong friend with Patton and myself. You were a very friendly cat who loved cuddling and hanging out with everyone. I think that your happy place was finding a nice bed or couch to cuddle up with someone. And once you and Patton were comfortable being together, you two were always together.
Professor Meatball even came back for a few months, during which time you were thrilled to have someone else who you could steal food from again.
Professor Meatball then passed, and then you became good friends with Lollipop.
Unfortunately, Patton passed away, and then it just became you and Lollipop for a while.
Even during this time, you still remained your cuddly self.
Eventually, we adopted Boba Milk Tea, and you got another cat to hang out with, and got to show a young kitten how to be a cat.
Unfortunately, these blissful times didn’t last too long. Shortly after we adopted Boba, you were diagnosed with an aggressive form of Cancer, large cell lymphoma. We quickly got you a surgery to remove a 1.6 cm mass from your intestine and got you started on the CHOP chemotherapy protocol. I know that the cancer made this last year rough on you. After your surgery, you had to stay in a cage to limit your movements to prevent tearing your stitches.
Despite the discomfort that you were in, you still like being around the family, as long they didn’t cause you to move around too much.
Eventually, you did recover from your surgery, and while the chemo treatment would leave you feeling a bit ill for the day, you still got to have several good days hanging out with Boba and Lollipop and cuddling on the bed. We even got you your own isolated space using a cat enclosure and a microchip cat door, so that that when you were not feeling well, you could have a place you could isolate from the rest of the family and rest.
This was a good time for you, you were surrounded by your family and got to enjoy every day. You managed to finished the CHOP chemotherapy protocol in January of 2026. At first it seemed like you were doing well, however in February you started having symptoms of cancer again. We decided to not attempt more chemotherapy, as while you still enjoyed living and spending time with your family, the chemotherapy treatments themselves were increasingly taking a larger and larger toll on your health, taking a longer and longer to recover from.
I know your last couple of months were rough. You had always been our stomach with legs who would eat everything, however during these last few months it was tricky getting you to eat, and I offer you food several times throughout the day to ensure that you were still eating enough. During this time, your belly distended and filled with fluid. I can’t imagine that was comfortable for you. Despite all of that, you still enjoyed hanging out with your family and cuddling at night. You were amazing. You really loved all of us so much.
On the morning of Friday, May 8, 2026 at 11:10 am, you passed away. The week prior, your symptoms had continued to worsen, and you were eating less and less every day. I spent the night with you, and in the morning I carried you to the patio where we watched the sun rise together. You spent your last morning watching the sun from your favorite place on the patio surrounded by your whole family to spend your last few moments with your family that you loved.
I know that you loved your family with Boba, Lollipop, Meatball, Patton, Angela and myself. We all miss you JoJo. I miss you JoJo. I am going to miss you cuddling close every night, and waking up with you demanding your breakfast. I am going to miss you jumping onto my lap and demanding to sit there for hours. Our home isn’t going to be the same without you in it. However, I know that you stayed with us for as long as you could, and that now you have achieved your eternal peace and an endless supply of tasty food and friends to cuddle with.
Born: Estimated in 2015 Adopted: 2017-12-20 Died: 2024-10-02
Patton was diagnosed with hypertrophic cardiomyopathy on 2022-11-28, which caused the muscle around his heart to thicken. This caused heart failure, meaning that his heart did not pump enough blood to his body, and also caused secondary issues such as lungs filling with fluid and blood clots. For 22 months, we were able to manage Patton’s condition with medication given three times per day and with frequent visits to the cardiologist. Unfortunately, hypertrophic cardiomyopathy is a progressive disease with no cure.
Eulogy
Patton, you were an amazing cat. You filled every room with such love and joy. I remember the first time that I met you. I was looking to adopt a cat who would want to go outside and not get stuck living in a small apartment. I remember meeting many wonderful cats at Peter Zippi as I walked through several rooms with many playful cats. You were in the last room that I visited. You were sitting on top of a cat climber basking in the sunlight. You were recovering from your surgery, where all of your teeth had been extracted due to your stomatitis. I had been told that you had been kept in the city pound for the prior six months as evidence for a court case. During this time, you were blocked from receiving the proper medical care while being kept in a small cage. Despite this, when I came into the room to visit, you came alive. You perked up and wanted to be pet, and then, after a few moments, you stood up and walked over to the door. I could tell that you were ready to leave. I could tell that you wanted a better life and that you were tired of being trapped indoors.
While we did not adopt you that day as you were still recovering from your surgery, I came back to visit you a second time and then adopted you on the third visit.
I don’t think you knew what you were getting yourself into at the time, but I hope that you were ready for the adventure. I remember that on the car ride home, you sat in my lap and looked out the window. Even from when I first met you, you were always a curious cat and liked seeing the world around you, and you never liked staying in your cat carrier.
When we got home that first night, you walked around my bedroom smelling the different things and ate some food. Eventually, you decided to hide under my desk. You were in a new environment with new people who you did not know well, and I could understand you being scared. However, once I went to sleep and turned off the lights, you jumped onto the bed and put your but into my face to cement the relationship in the standard cat way. You then slept in the bed all night, and we have been inseparable ever since.
Within a few weeks of adopting you in southern California, we flew back to Maryland. I was entirely unprepared for the flight with you the first time. I had you in a standard cat carrier and planned to keep you under the seat during the flight—as is typically done. However, shortly after the flight took off, you started panicking and thrashing around to get out of the cat carrier. I had to hold you in my lap for the entire flight, rocking you back and forth for the whole of the 6 hours of the flight to try and keep you calm during the flight.
Eventually, once the airplane landed, you calmed down. In the taxi from the airport, you were a curious cat and looked out the window the entire way. Again, once we arrived at my apartment, you immediately acquiesced. You were always impressive in how adaptable you were to new environments, with this being the second new place that you were introduced to within a matter of weeks of having been adopted.
Within the first month of adopting you, I started training you to walk on a leash. You never did like the harness, however you did like going outside. Amazingly we were able to start with some basic walks around the building within a few weeks. I think that you enjoyed being able to smell the plants and scratch the trees, as a normal cat does.
I even dragged you outside of the apartment so that you could experience snow for the first time. I think you thought I was crazy for taking you outside when it was cold and wanted to go back inside to the warm apartment.
When we weren’t out walking, you spent your days watching the birds at the bird feeder or relaxing on the bed or your cat climber.
After several months of being in Maryland together, we returned to California for a week-long vacation. This, of course, meant that I took you on an airplane for the second time. However, this time, I was much better prepared. I had registered you so that you could sit on my lap during the flight and not have to stay in the cat carrier. While you panicked when the airplane took off, you calmed down within the first 10 minutes of the flight and spent most of the flight looking out the window and enjoying being pet.
While flying was never enjoyable, you did prefer flying and coming along on vacations to being left behind. In total, you took around a dozen flights, each around 6 hours long, flying back and forth across the country. You often got compliments from the flight attendants for being so well-behaved on the flights.
Traveling with me meant that you got to experience lots of different places. Often, we would just walk around the different walking trails in the area.
I think one of your favorite places that we traveled to was Washington State. There, we spent hours a day walking around in the forested areas. You would walk up to 4 miles per day maintaining about 1 mile per hour.
When you got tired, you would meow and ask to be carried in the cat carrier backpack that I had. You would rest in the backpack while still looking out at the trees.
You even hiked several miles up a mountain to the top of Poo Poo Point and got to look out at the sunset.
The true winners of the COVID lockdowns were pets; You were undoubtedly included in this. During the lockdowns, I spent all of my time with you. During the day, I would take you and my laptop to the park. You would enjoy climbing in the trees and chasing squirrels. A few times, I lost you for several minutes as you were hiding in the bushes. When you were tired or it was too hot, you would come and sit beside me in the shade.
After nearly a year of it being the two of us hanging out, I decided to fly back to California so that we could be around family, as the COVID lockdown seemed to be continuing without end. I tried to prepare us the best that I could for the airport. I tried to modify a mask so that you could wear it while on the airplane, but I was ultimately unsuccessful in finding something that you were willing to tolerate.
Once, back in California, we ended up staying in California for several months as the COVID lockdowns continued. There, you got to go run around outside in the backyard yourself every day.
You became friends with Blacky, who, up till that point, was a feral cat who rarely interacted with humans. I think that you taught Blacky how to be a domesticated cat and how to enjoy hanging out around humans. I think that Blacky taught you how to catch lizards and other small animals in the backyard. Because of your influence on Blacky, Blacky is now a fully domesticated cat who spends his nights sleeping and relaxing indoors.
Because you didn’t have any teeth, when you caught lizards or birds, you would rarely kill them. Often, you would bring the lizards into the house and let them lose. I think that there were a few lizards that you probably caught and released multiple times as a result.
After several months of staying in California, the COVID restrictions started to lessen, and I decided that we should go back to Maryland. I am sure that you missed your days playing in the backyard in spending your days with Blacky.
Thankfully, you didn’t have to wait too long before your family grew again. Within a few weeks of being back, you met Jojo.
That first week there was a lot of growling as you were a bit stunned to have another cat in your space.
However, you eventually became friends with Jojo.
We started leaving the patio door open all of the time. During the day, you two would always stay out on the patio watching the birds and enjoy the sun.
When it was cold or rainy, you would complain and ask for a nice warm day.
However, Professor Meatball was already a very old dog by the time you met her, so she was not around for too long in your life. After Meatball passed, your family changed again with the adoption of a new puppy. We adopted Lollipop. This changed your family’s dynamic again with a rambunctious puppy chasing you and Jojo around all of the time. On the day that we adopted Lollipop, I have the following photo of you and Jojo looking at each other questioning what is this new puppy that has just entered your home.
As always, you adopted Lollipop into your family. And You, Jojo, and Lollipop spent your days together hanging out. Lollipop even learned some cat-like behavior from interacting with you. Lollipop learned to tap others on their head with her paw from you. Lollipop also learned to lick herself clean like a cat.
You were also the only one of our pets who was calm enough that I was able to take a picture with you and Gerbil the Hamster.
While you were always loving and were the most friendly cat who loved your family, you always had health complications. When I first adopted you, you had recently had all of your teeth extracted due to stomatitis, causing your mouth to be inflamed. While this helped your mouth be less inflamed, we still had to be careful with your mouth. For a while, we went to the vet as frequently as once a month to get laser therapy to reduce the inflammation in your mouth.
For several years, you did not have any active health complications, and you were a healthy cat. However, your health didn’t last. On 2022-11-28, you were diagnosed with hypertrophic cardiomyopathy and heart failure. I noticed that you had seemed less energetic than your usual self and that you seemed to be isolating yourself a lot more than usual. Usually, when you were uncomfortable, it corresponded with your mouth being inflamed. However, this time, your mouth did not appear inflamed at all. We got you a blood test to see if we could find anything that might be informative. It took a few days to get the results, but it came back that your ProBNP was off the charts with 1500, indicating that your heart was significantly stressed. We got an appointment with the cardiologist a week later. They found small clots in your bloodstream and that your heart’s lower chamber was nearly twice as large as it should have been. I was told that you would be lucky to live six months, given your condition at the time. You managed to live for 22 months.
I gave you your medication three times per day as it seemed to help you stay stable and able to breathe comfortably throughout the day. You even learned when it was time for your medication and would come and remind me.
We went to the cardiologist every three months. Every time that I took you to the cardiologist and we adjusted your medications, it was like you got a new lease on life. While we did not keep doing long walks outside when you were feeling well, you would ask to go outside. We would walk around the block together, and you would enjoy smelling the plants. I would also take you to the park, and you would enjoy running around in the bushes for a few minutes before you would get tired and sit down somewhere to rest.
At last, your health could not be maintained forever. The few days before you died, you had started to have a harder time breathing. One of the side effects of hypertrophic cardiomyopathy is that your lungs fill with fluid. We tried to maintain the fluid build up the best we could with medication, however, with the medications it was a balancing act between what your lungs needed to drain the fluid, and what your kidneys were able to tolerate. When the fluid buildup becomes too great, the option is to drain the fluid from your lungs using a syringe in a procedure called thoracocentesis. I had wanted to avoid the procedure for as long as possible as the procedure comes with lots of other complications, such as requiring anesthesia, and it would potentially require that the procedure be repeated as frequently as every two weeks.
Unfortunately, the time eventually came when we could no longer address the fluid buildup with medication alone. On the morning of October 2nd, 2024 I took you to the pet emergency room to have the fluid drained from your lungs. The day before, you seemed very uncomfortable as you were having difficulty breathing. I was up most of the night watching you sleep. Your breathing was very heavy.
On the way to the pet emergency room, you were in the carrier as you always were, looking out the window at the trees went by as you always did. I was hopeful that this would be just like the earlier vet visits, where afterward, you would feel better just like you always did after a vet visit. I think that you were similarly hopeful that you would feel better after the vet visit, as that is what usually happened.
When we got to the pet emergency room, we were seen immediately. Your blood oxygen levels were faily low. I got to hold the oxygen tube up to your nose for several minutes. You enjoy that. Even being hooked up to the various sensors, you were still a happy cat. You wanted to be pet, and I could tell that you were trusted me to take care of you.
You died shortly after the procedure at 11:50 am on October 2nd, 2024.
You lived as long as you could, and you enjoyed life right up to the last moment. You kept going outside and enjoying the outdoors, playing with and loving your family. I think that you left right as keeping you alive started to become painful.
Here is the last photo that I took of you when you were alive on the afternoon of October 1st, 2024.
Miscellaneous
Patton at a campfire near the water in Washington state.
Patton on the dock in Washington State.
Going down a slide at a park with Patton. Patton was a very confused cat that day.
Patton, you always loved to play fetch with toy mice. The toys would be scattered around the apartment at all times. Unfortunately, Lollipop started destroying all of the toys and we could no longer leave them around.
When it comes to passing along digital accounts after death, existing services operate as a dead man switch, sending an email after some amount of time has passed. This requires that you trust your chosen service not to close down, that the dead man switch will not get accidentally triggered before you die, and to not get hacked causing your sensitive information to get leaked. To me, this problem could be reasonably solved using cryptography. Using Shamir’s secret sharing, we can split a message into N parts such that as long as the number of people attempting to decrypt a message is less than N, the message can not be decrypted. Furthermore, we can use asymmetric encryption so that multiple messages can be encrypted rather than requiring a single message to be predetermined that will be sent along. Building on top of the PGP ecosystem means messages can be encrypted from the command line if one so chooses, and the cryptographic primitives will be secure.
However, this combination of Shamir’s secret Sharing and PGP does not make for a good user interface for non-technical users. As such, I created Encrypted Messages for the Event of Death as a self-contained webpage that uses OpenPGP.js and Shamir secret sharing to expose the necessary operations to create encryption keys, encrypt messages, and decrypt messages. This means that by providing loved ones with a link to this webpage as well as encrypted messages, they should be able to figure out how to decrypt an encrypted message, provided that they can copy and paste the encrypted messages into the webpage.
I think that there are many people who are surprised that Large Language Models (LLMs) that predict the next word act intelligently and are capable of solving many challenging tasks. In my opinion, the success of LLMs is not surprising. In this blog post, I will explain why I think LLM’s success was obvious.
So, around two years ago, during a discussion with some colleges, I coined the term “GPT-\(\infty\)” to represent language modeling in the limit of infinite power and infinite data.
let it be known that neural LM in the limit was coined gpt-? by @matthewfl
And I think that this “in the limit” thinking is helpful in understanding the success of modern Large Language Models. So first, let us discuss what language modeling is and what it would mean to take language modeling to the extreme “in the limit.”
What is Language Modeling?
So, what is generative language modeling? Language modeling is a probabilistic model over a sequence of words, usually written as follows:
Where \(f(\cdots)\) is a function that returns a real number and is typically learned from data. The “\(\propto \exp(\cdots)\)” in this equation converts the real number returned from \(f(\cdots)\) into a probability distribution over possible next tokens \(w_i\). A long sequence of words can be generated by repetitively evaluating \(P(w_i | w_{i-1}, w_{i-2}, \ldots, w_0)\) to determine what is the most likely next word in the sequence conditioned on the previously generated words.
For example, suppose that we have the sequence “The moon is made of,” and we want to determine the next word. We will evaluate \(P(\text{rocks} | \text{The moon is made of})\), as well as \(P(\text{cheese} | \text{The moon is made of})\). Both the words “rocks” and “cheese” are given some probability of being the next word. In the case of generation, we choose the word that has a high probability, either greedily or according to some randomized process.
\(P(\text{rocks} | \text{The moon is made of}) > P(\text{cheese} | \text{The moon is made of})\)
In the case that we want to evaluate the probability of a longer sequence of words, we can multiply the \(P(w_i | \cdots)\) together, where each \(P(\cdots)\) is used to evaluate a single word. For example,
models the probability of the phrase “the moon is made of rocks.”
Backing Off A Language Model
When building language models, researchers have to make many decisions to develop a model that is tractable. For example, there are several ways that the function \(f(\cdots)\) can be defined. These days, \(f(\cdots)\) is usually a large neural network (a transformer), which is trained using gradient descent. However, neural nets are not the only way to define a language model. For example, early n-gram language modes defined \(f(\cdots)\) as the ratio between counts of phases that appeared in a corpus. For example, a bi-gram model only conditions on the previous word and is defined as follows:
We can observe that the bi-gram model is very backed off, as it only depends on the previous word. Hence, the probability distribution represented \(P(w_i | w_{i-1}, w_{i-2}, \ldots, w_0)\) is the same as \(P(w_i | w_{i-1})\) under the bigram model. As a result, when people write the \(P(\cdot)\) equations using backed off language models in a paper, they will usually remove the \(w_{i-2}, \ldots, w_0\) from the equation they are writing. For example:
Writing the \(P(w_i | \cdots)\) this way indicates which parts the \(f(\cdots)\) function is able to use. Engineers will claim that this approximation is “good enough” for whichever task they are attempting to solve. Note, just because we choose to ignore the \(w_{i-2}, w_{i-3}, \ldots, w_{0}\) does not mean it does not exist.
So, now that we have a basic understanding of language modeling, and backing off a language model, what does it mean to language model in the limit? Let us imagine a theoretical language model that does not back off from anything. In other words, it conditions on absolutely everything.
\(P(w_i | \text{EVERYTHING BEFORE } w_i) \propto \exp(f(w_i, \text{EVERYTHING BEFORE } w_i))\)
Furthermore, in the limit, we will say that this language model has been trained with everything. This includes all data that existed in the past and all data that will exist in the future (hence everything). Because the infinite language model has access to all data, this means it always accurately predicts the next word.
For example, the infinite language model conditions on who is speaking which changes the probability of the next word. In the case of the moon rocks example, if we are modeling a scientist vs a 5-year-old, then there are likely to be different answers
Here, the language model knows that I (Matthew) am the person speaking. It also knows what the day is. It even has information about what I actually ate, and it knows that I will answer this statement truthfully. Note that what I actually ate is not recorded anywhere. I did not write it down on a piece of paper or tweet about it online. In other words, the infinite language model has access to all data, not just the data that is online.
It might be better to call the infinite language model an omnipotent model in that it has access to everything and even knows the next word with 100% accuracy. Hence, it is not really appropriate to think of the “infinite language model” as a probabilistic or learned model.
Rather, the thing that we are interested in is that our “omnipotent and infinite” model is a function \(f_\infty(\cdots)\) that takes the entire world prior to \(w_i\) as an argument and returns a real-valued number that selects the next word.
Using the “In The Limit” Language Model
So how do we make use of the \(f_\infty(\cdots)\) function?
Neural networks are universal function approximators. This means that for any function \(\hat{f}:\mathbb{R}^n \to \mathbb{R}\), that takes a real-valued vector (\(x \in \mathbb{R}^n\)) as an argument and returns a real value (\(y \in \mathbb{R}\)) as the result, there exists a neural network \(f_{\text{neural}}:\mathbb{R}^n \to \mathbb{R}\), that can approximate the function \(\hat{f}\) to a desired degree of accuracy.
To train the neural network \(f_{\text{neural}}:\mathbb{R}^n \to \mathbb{R}\), one simply needs to collect many inputs and outputs samples \(\langle x, y \rangle\) from the function \(\hat{f}\), and then use those samples to train the \(f_{\text{neural}}\) function. This is exactly what we already do when training a neural network!
In other words, if we collect a lot of samples from the “omnipotent and infinite” language model \(f_\infty\) and use that to train \(f_{\text{neural}}\), then we can approximate this function. Thankfully this is easy! All text that exists are samples from the \(f_\infty\) model.
For example, suppose that we prompt the \(f_\infty\) model with “reddit post written by bob123 on July 16, 2006”. The \(f_\infty\) model will exactly know the post by b0b123, and the \(f_\infty\) model will generate “Religion and politics are always interesting.” This sentence can then be used as training data for the \(f_{\text{neural}}\) model.
Hence, gathering data to train \(f_{\text{neural}}\) can be done by simply collecting all written text and training a neural language model in the usual way.
Furthermore, we will create better approximations to \(f_\infty\) by conditioning on more of the input to \(f_\infty\), meaning creating larger prompts for Large Language Models, and by making the approximation better by creating larger neural networks! In other words, bigger equals better.
Is the “In The Limit” Model Intelligent?
Large language models seem to act intelligently. So a natural question is the \(f_\infty\) function, that neural language models approximate, also intelligent? Admittedly, this question is a bit ill-formed. The \(f_\infty\) model is “omnipotent and infinite.” It does not need to be intelligent. It already knows everything.
For example, suppose that I have a time machine and go back in time to December 6, 1941, and predict that on December 7, 1941, Japanese planes will attack Pearl Harbor in Hawaii. From the perspective of the people living in 1941, I would appear to be a very intelligent person as I have apparently analyzed a bunch of data and accurately predicted the future. However, knowing that I was a person living in 2024 with knowledge of history, the only thing that I have done is recall a fact that I read in a history textbook.
What is Intelligence?
So if \(f_\infty\) is not intelligent, is training \(f_{\text{neural}}\) to approximate \(f_\infty\) going to enable us to build intelligent agents?
First, let us try to define what it means for a system to be intelligent. A plausible definition of intelligence could be having the ability to predict the future and then using those predictions to exhibit behavior that is favorable to the agent. I am using the term “favorable behavior” loosely here in that the behavior does not have to entirely come from a “conscious” decision by the agent.
For example, suppose that the agent is a hunter and is trying to catch an animal that it wants to eat. If the agent can accurately predict where the animal is going to be, then the agent is going to have a better chance of catching the animal. The favorable behavior in this case is getting resources (food) that are needed to survive. This behavior is driven by some innate instinct to get food and survive.
A more modern version of predicting the future these days might instead look like trying to predict the price of a stock. For example, if an agent can accurately predict the price of Nvidia stock, then it can place trades (bets against other traders) that will be profitable. In the case of the \(f_\infty\) model, the model is omnipotent, so it knows the answer. Hence, it would win every bet. However, if we are not an omnipotent agent and are limited by the constraints of time, then the agent will have to read through corporate reports and compare trends with historical data to make an “educated guess” about the future stock price. This is conceptually what a human financial analyst does. Here, we say that the agent is acting intelligently because the agent does not have direct access to the future (like \(f_\infty\)) and instead must use its existing sources of knowledge to make an “educated guess.” Hence, the agent must represent their guesses using a probability distribution of potential outcomes:
\(P_{\text{neural}}(\text{nvidia stock closed at \$900 at the end of 2024} | \cdots) = .001 \)
\(\vdots \)
\(P_{\text{neural}}(\text{nvidia stock closed at \$800 at the end of 2024} | \cdots) = .001 \)
\(\vdots \)
\(P_{\text{neural}}(\text{nvidia stock closed at \$600 at the end of 2024} | \cdots) = .001\)
This is in contrast to \(P_\infty(\cdots)\) that knows the correct answer and creates a “distribution” that is entirely peaked at the correct answer:
\(P_{\infty}(\text{nvidia stock closed at \$900 at the end of 2024} | \cdots) = 0\)
\(\vdots \)
\(P_{\infty}(\text{nvidia stock closed at \$875.23 at the end of 2024} | \cdots) = 1\)
\(\vdots\)
\(P_{\infty}(\text{nvidia stock closed at \$700 at the end of 2024} | \cdots) = 0\)
Conclusion
So, in conclusion, Large Language Models are being trained to approximate the “in the limit” \(f_\infty\) function by being trained on the collection of all text. As we build larger LLMs and use more data, we will train neural nets to better approximate \(f_\infty\), which will make the agents appear more intelligent. Because LLMs, like humans, are unable to know the future, they must deal with ambiguity and instead create a distribution of potential outcomes. Hence, LLMs exhibit seemingly intelligent behavior.
Finally, I note that this “in the limit” argument says nothing about what is the optimal architecture or that transformers, or even neural networks, are the best way to approximate \(f_\infty\). Rather, my claim is that there exists a function \(f_\infty\) such that, when approximated well, will result in agents that act intelligently.
My PhD on Declarative Programming Via Term Rewriting, which I completed at Johns Hopkins University, is done. https://matthewfl.com/phd
This research project was about developing a declarative, weighted logic programming language for machine learning, artificial intelligence, and natural language processing applications. The programming language we were researching was interesting because it allowed for programs that do interesting probabilistic and symbolic reasoning to be concisely expressed in a few lines of code. It accomplishes this by allowing the programmer to leave out as many details as possible about how the program is executed. This is similar to a database, where the database needs to automatically figure out how to retrieve the data given a high-level declarative query.
To make this work, I created a relational algebra, which is capable of representing entire programs. To make the system flexible enough to find a good execution strategy, I created a term rewriting approach that includes hundreds of rewrite rules to run the program. This is similar to rewriting an expression like “2 + 3” as “5” where both of these expressions are semantically equivalent.
To make the term rewriting relational algebra approach tractable, I additionally had to redesign many of the traditional approaches that programming languages are implemented. For example, I created a new way to think about memoization (dynamic programming) to make it work with our system. Additionally, I created a (JIT) compiler for our term rewrite system because the naive implementation was too slow for real world use.
In the end, this was an interesting research project. However, I think that this work was set a bit too firmly in the realm of symbolic systems for AI (the AI paradigm of yesteryear). Hence, I do not know if this is applicable to modern only big neural AI that is dominating. Eventually, I do think that this work may see some use. The reason is that while pure neural creates really cool demonstrations, it will also fabricate information. This creates an issue when these systems are deployed into applications, and that is a problem for their usability in industry. Hence, having a system that incorporates weighted reasoning (necessary for neural networks), and symbolic reasoning into a single system is a very powerful programming paradigm.
I present a new approach to implementing weighted logic programming languages. I first present a bag-relational algebra that is expressive enough to capture the desired denotational semantics, directly representing the recursive conjunctions, disjunctions, and aggregations that are specified by a source program. For the operational semantics, I develop a term-rewriting system that executes a program by simplifying its corresponding algebraic expression.
I have used this approach to create the first complete implementation of the Dyna programming language. A Dyna program consists of rules that define a potentially infinite and cyclic computation graph, which is queried to answer data-dependent questions. Dyna is a unified declarative framework for machine learning and artificial intelligence researchers that supports dynamic programming, constraint logic programming, reactive programming, and object-oriented programming. I have further modernized Dyna to support functional programming with lambda closures and embedded domain-specific languages.
The implementation includes a front-end that translates Dyna programs to bag-relational expressions, a Python API, hundreds of term rewriting rules, and a procedural engine for determining which rewrite rules to apply. The rewrite rules generalize techniques used in constraint logic programming. In practice, our system is usually able to provide simple answers to queries.
Mixing disparate programming paradigms is not without challenges. We had to rethink the classical techniques used to implement logic programming languages. This includes the development of a novel approach for memoization (dynamic programming) that supports partial memoization of fully or partially simplified algebraic expressions, which may contain delayed, unevaluated constraints. Furthermore, real-world Dyna programs require fast and efficient execution. For this reason, I present a novel approach to just-in-time (JIT) compile sequences of term rewrites using a custom tracing JIT.
To celebrate the one year anniversary of adopting Patton, I would like to take a moment to encourage cat owners everywhere to walk their cat. After a year of walking Patton, I have been able to get him to go up to 4 miles on a single walk. I have come to believe that Patton often enjoys walking as sometimes he chooses to continue walking instead of stopping early.
The First Time Walking
When I first started trying to walk Patton I had found that there was an abundance of advice online about how to train a cat to walk on a leash. I have come to think that with cats there might not be a single strategy that works (like there is with dogs) and I wouldn’t get discourage if the first thing that you try ends up failing.
The first time that I put a harness on Patton, he was about 2 years old already and I had only adopted him a few weeks earlier. (So he was doomed to walk on a leash from the start with me.) Now, a lot of the advice that I found online talked about getting a cat used to the harness first. However, Patton really hates the harness, even after a year of using it he would just go pout if it was left on while he was inside. So, instead of trying to get him used to the harness while indoors, I only ever use it while outside and the moment that we get back, I end up taking it off. With this arrangement, Patton will even wait by the door right after getting back for me to take the harness off.
The second trick to getting Patton to start walking was figuring out how to motivate walking while outside and on a leash. What I eventually settled on was rewarding returning to my apartment with food. This was fairly natural given the first few times that I tried to take Patton outside all he wanted to do was run back inside. This meant that I would carry him outside some short distance and then let him run back (while still on the leash). This means that these walks are really short on the matter of minutes where I would put the harness on, carry him a few feet from my door, let him run back, and then feed him.
Extending the Distance
Once I had Patton doing short distances, the trick was then to being extending the walk into something more than just running back to my apartment. This started as carrying him outside one way and then making him run back another way. Essentially this was trying to close a loop so that it would begin to look more like a walk. Now, this required a bit of handling on the leash to tug Patton along some alternate path. During this time, I also planned goals during the walk which I began to associate with the food reward that Patton would get at the end of walking. The goal that I started with was just walking around the perimeter of my apartment building.
What to Expect
Walking a cat is not like walking a dog. When walking a dog, they will generally follow along after relatively minimal training. Cats are instead leading the walk. When I take Patton to a city park, he often want to spend a lot of time smelling all of the plants in an area or laying down in the bushes and take a nap instead of walking around. I have found this a good time to bring a book and catch up on reading.
While “slow” or relaxed walking is the norm inside of a city, I have found that when I take Patton on more isolated trails (less dogs) then he is more eager to walk. If there is a single obvious path to follow, then Patton is more than happy to take the lead in these cases and have been able to walk him up to 4 miles under these ideal circumstances.
This is a newly published repository from an experiment that I started during the summer to attempt to optimize Python’s runtime without impacting compatibility with C models and existing libraries.
There currently exists frameworks such as PyPy and Truffle/Graal which will generate a JIT when you design your programming language inside of their framework and use their compiler to generate a custom binary which implements a JIT for a given language. One problem with these frameworks is that they require that an existing language is reimplemented essentially from scratch using a subset of Python or Java respectively. Additionally, once a programming language is reimplemented, any existing modules which interface with internal aspects of the interpreter (any python C module) will not be compatible and will have to be rewritten.
Redmagic is similar to PyPy and Truffle/Graal in that it tries to be a framework for creating a JIT however it is different in that it tries to work with an existing C or C++ interpreter requiring only a few annotations inside the code to identify loops at the user level of the program. (cPython example) It then generates traces of a user’s program by switching between letting the language’s interpreter run normally and on top of a virtual machine which records all instructions and branching directions. Unlike other JITs it does not reorganize how memory is laid out and even goes as far as simulating pushing and popping of C level stack frames. This means that at any point while running inside the virtual machine or inside the generated code, the system can resume the “normal” code simply by jumping to the corresponding instruction in the original interpreter. This does come with the downside that it inherits all memory layout and pointer dereferencing performance issues that were present in the original interpreter.
Results: After much work on Redmagic, I have observed very slight (<2%) performance improvements in limited cases when working with cPython. The issues of memory layouts (explored further in this post) seem to contribute significantly to Python’s performance issues and those are not addressed at all by the Redmagic implementation. Additionally, it is not clear that these would be easy to address from Redmagic itself given that it is looking at a program from the level of x86 assembly instructions vs higher level representations where data-structures can be easily recovered. I believe that there might be cases, possibly in math routines, where memory layouts have already been optimized and possibly allowing for more clever uses of branching could prove beneficial to performance.
This post is from a recent conversation that I had about the cost of abstractions in various languages. In choosing a programming language for a project, it is important to choose a language that gives a good mix of “time to develop” and “performance.” The first tends to be obvious from experience. However, for many, the performance of a programming language (and its implementations) is somewhat opaque. I am going to demonstrate the differences between Python, Java, and C++, as this gives a good sample of the differences between programming implementations. We can think of Python as representative of the general class of interpreter-based programming languages such as Ruby and Perl, and Javascript before 2005. Java represents the current state of the art in JIT technology and should generalize to general JVM targeted languages and even languages such as Javascript, which have seen countless hours invested in developing new implementations of the language. Finally, C++ is a “low level” language, however, it features a number of unique features, such as templates and stack allocation, which allows for zero cost abstractions which is sparsely seen in other languages.
What is abstraction
Abstraction in this post means the ability of the programmer to wrap a series of methods and data into some object which we are going to use throughout our program. An example of abstraction might be a class LogNumber which abstracts away the fact that we are representing some numbers inside of a log space instead of a linear space. This is fairly standard practice in machine learning applications and might even be necessary in some cases where the magnitude of the number is smaller than the range of a floating point number. If we have this abstraction then we can write an expression such as: LogNumber + LinearNumber and have the LinearNumber automatically converted into log space and thus we will get the correct behavior from our program. If we are programming without this abstraction and simply using primitive types, and we accidentally write float_in_log + float_in_linear we are going to get a number that is neither in log space or linear space and this is a bug. One of the most famous examples of this bug is with the Mars Climate Orbiter crashed due to a units mismatch between standard and metric system.
For the remainder of this post, we consider a simplified “LogNumber” class, A which is using a single 32 bit signed integer and getter and setter methods. One could easily imagine there being multiple getter and setter methods for when one wants to set a linear number to a log space number etc.
# Python
class A:
def __init__(self, a):
self._value = a
def get(self):
return self._value
def set(self, a):
self._value = a
// Java
class A {
private int value;
public A(int a) { value = a; }
public int get() { return value; }
public void set(int a) { value = a; }
}
// C++
class A {
private:
int32_t value;
public:
A(int32_t a) : value(a) {}
int32_t get() { return value; }
void set(int32_t a) { value = a; }
}
Memory overhead
First, let us consider the impact on memory that this abstraction has in each of these languages. Memory makes since as a place to start it is generally understood that the less memory that we use the more that we can fit into ram. Additionally, on modern hardware, accessing main memory tends to be a major bottle neck for performance with a read from main memory taking ~100 cycles while a local processor caches takes 10-20 cycles. As such, having an object which is twice as large means that we can fit half as many objects inside our processor cache and thus will end up performing costly accesses to main memory more often. Remember, while reading this next section, we are just wrapping a single 4 byte integer.
# Python
a_python = A(5)
// Java
A a_java = new A(5);
// C++
A *a_ptr_cpp = new A(5);
A a_stack_cpp(5);
Python: First for Python, in constructing the A class, we are going first to create a PyInstanceObject which contains 3 pointers plus the PyObject_HEAD which is 3 pointers plus a size_t bringing the size of this struct up to 56 bytes plus malloc overhead. (Note: the malloc overhead depends on the implementation of malloc used and could even be changed at runtime using something like LD_PRELOAD). Next, to actually save _value we have to construct the hash map that is going to back all the elements for this class instance. This means creating a PyDictObject which is a PyObject_HEAD, 3 size_t, 2 pointers, and 8 preallocated hash map slots for which each slot contains a size_t and 2 pointers bringing up the size of this object to 264 + malloc overhead. The number 5 in this case is a small integer and thus is already interned inside the python interpreter and the hash map key _value would be shared between all instances of this object and so we are not going to count it. Finally, we are going to have to maintain a pointer on Python’s stack to the object a_python that we just constructed. All together then this brings our total size to 328 + 2 * malloc overhead. Note: We could reduce the object size somewhat by using Python’s __slots__ feature which should avoid allocating an oversized hash map to back this object, however our object size is still going to be in the 100s of byte range.
Java: Next with Java, there is an 8 byte header that is added to all objects which contains information about the type of object and object state w.r.t. locking etc. (more info) Additionally, Java will round the size of objects up to the next 8 byte increment which means that there will be 4 wasted bytes inside this particular object. Finally, we need to store a pointer to this object on our stack. One of the nice tricks in Java for saving memory is pointer compression where a pointer will be 4 bytes instead of 8 which is a significant savings given that Java programs tend to use a lot of pointers. (pointer compression info). Together, this means that there will be 20 bytes in memory corresponding to this object.
C++: In the first case with a_ptr_cpp we can see that the object size will be 4 bytes as one would expect given the C++ standard. There will also be the additional malloc overhead associated with this object. This brings the total size for the a_ptr example to 12 + malloc overhead when including the stack pointer. In the second case with a_stack_cpp we have this being directly allocated on the stack which means that we have no pointer or malloc overhead or pointer to the object, thus the total size is only 4 bytes. The fact that we are able to take a primitive type (int32_t) and wrap it inside some class and still consume the exact same amount of memory is what it means to have a zero cost abstraction.
Registers
Once C++ is compiled with some optimizations or a Java program has been running for long enough, it is feasible that both a_ptr_cpp and a_java are entirely stored inside a register saving 8 and 4 bytes respectively. Moreover, in the a_stack_cpp case we might have the integer value stored in a register, which means that the memory used in this case is 0 bytes.
Escape Analysis
For the C++ and Java case if a compiler can prove during optimizations that a dynamically allocated structure is not going to leave a method, then it is possible for that compiler to transform that object into a stack allocated object. This means that even for a_java and a_ptr_cpp could end up having zero memory consumption in the right circumstances.
// Java
{
A a_java = new A(5);
a_java.set(6);
System.out.print(a_java.get());
// we never let anything outside this block get the reference to a_java
}
// C++
{
A *a_ptr_cpp = new A(5);
a_ptr_cpp->set(6);
cout << a_ptr_cpp->get();
delete a_ptr_cpp;
// the compiler is able to see where this object is constructed and destroyed
// if we didn't delete it, then the fact the leak could still be considered an escape in C++
}
Array overhead
Arrays are basic primitive in nearly all languages when it comes to efficiently storing a number of similar objects. In the case of numerical processing applications, our main performance overheads are going to come down to how efficiently we store numbers and are able to access these values.
# Python
arr_python = [A(i) for i in range(10)]
// Java
A[] arr_java = new A[10];
for(int i = 0; i < arr_java.length; i++)
arr_java[i] = new A(i);
// C++
A *arr_ptr_cpp[] = new A*[10];
for(int i = 0; i < 10; i++)
arr_ptr_cpp[i] = new A(i);
A arr_obj_cpp[] = new A[10];
for(int i = 0; i < 10; i++)
arr_obj_cpp[i] = A(i);
std::vector<A>; vec_obj_cpp(10);
for(int i = 0; i < vec_obj_cpp.size(); i++)
vec_obj_cpp[i] = A(i);
A arr_stack_cpp[10];
for(int i = 0; < 10; i++)
arr_stack_cpp[10] = A(i);
Python: First for python, when constructing a list we create a PyListObject which contains the PyObject_HEAD, a pointer to the head of the list and a size_t for the size of the list for 48 bytes. The list itself is simply a list of pointers to objects. Therefore the list object on its own will be 128 + 2 * malloc overhead. For every object, we are then going to have the same as we had above with 348 per object. This brings the total of this to 3608 bytes + 22 * malloc overhead.
Java: With Java, there are essentially two types of arrays. The first is an array of a primitive type (such as int[]) where the value of the integers will actually be stored inside the array itself. These arrays can be considered very efficient since there is a small overhead when storing a large number of primitive values. However, in this case, our array does not contain primitive types and instead must has to be an array of pointers. This means that the array itself will have the 12 byte overhead for each object created and then 10 pointers for which each is 4 bytes, making the list itself 48 bytes which is divisible by 8 so we do not have any additional wasted space here. Each object in the list will then be 16 bytes as before and we have a reference on the stack bringing the total for this up to 212 bytes.
C++: Finally with C++, we can see that there exist a number of possible implementations for an array of objects for which each of these have slightly different memory implications. In the arr_ptr_cpp case we are creating an array of pointers which is conceptually equivalent to the Python and Java implementations. Including the stack reference to this, it takes 120 + 11 * malloc overheads bytes in memory. Note: we are are going to have to explicitly deallocate all objects inside the array when freeing arr_obj_cpp which requires additional cognitive overhead when writing this program. In the second C++ example arr_obj_cpp we are allocating space inside the array for our object instead of using a pointer to reference the array. This means that the size of the array will only be 40 bytes bringing this implementations memory consumption to 48 + 1 * malloc overhead when including the stack pointer. The third case with vec_obj_cpp uses the C++ standard library and would be a more acceptable way of writing the arr_obj_cpp example and will use 2 additional size_t (16 bytes) to track the array’s size and amount allocated (64 + 1 * malloc overhead bytes). The final case is constructing an array directly on C++’s stack which means that we are avoiding the stack pointer reference as well as the malloc overhead and this will only require 40 bytes. Again, we can see that C++ is capable of a zero overhead abstraction as in the last 3 examples the only overhead from directly using int32_t was O(1) bookkeeping.
Performance overhead
While the way in which data is stored is important, we also care about how these languages are going to perform when we go to execute our program.
// Java
A a_java = new A(5);
a_java.set(5);
System.out.print(a_java.get());
// C++
A *a_ptr_cpp = new A(5);
a_ptr_cpp->set(6);
cout << a_ptr_cpp->get();
A a_stack_cpp(5);
a_stack_cpp.set(6);
cout << a_stack_cpp.get();
Python: First, Python is the simplest language in the comparison, given that it is a simple bytecode interpreter. This means that it will not be performing any static compile time optimizations or attempting to compile away this abstraction. Looking at just the a.set(6) line, we can easily look at the Python’s bytecode using the dis library:
We can easily see that there are 10 python bytecode instructions. Some of these instructions such as STORE_ATTR and LOAD_ATTR represent hash table lookups to identify the _value and set slots. Additionally, nearly all of these instructions represent writes into memory given that Python uses reference counting, and by loading objects onto Python’s stack requires incrementing the reference count. To see full implementations of these byte codes you can look at ceval.c. From prior experience with python’s internals, I would guess that this line represents about 2000-7000 CPU instructions with over 30 writes to memory and 100 reads.
Java: With Java, it is a bit more difficult to exactly measure how much overhead there is when evaluating this instruction. This is because the JIT will be constantly generating new versions of this code which are more efficient. If we were to evaluate this instruction exactly once, then our bytecode will be running on an interpreter which is conceptually similar to python, but by not having reference counting and not backing every object with a hash map means that this is going to be significantly more efficient and about 100-500 instructions. After we have executed this statement a few times, the JIT will generate more optimized code. The exact code that is generated depends on a number of factors including if at the call site for a.set(6) if there exist multiple implementations of set that we must dispatch to (multiple classes implementing the same interface). Assuming that there will only be a single implementation of set, then the JVM will end up inlining and optimizing this down to 1 instruction which writes to memory.
C++: When using a pointer in C++, we can see statically that there is only a single implementation of A::set and so the compiler will likely inline this method call. This means that similar to the Java case it will have 1 instruction to perform the write into memory. In the second case with a_stack_cpp we might represent this instruction as a single write into a register. While both of these cases are going to be a single instruction, the later of writing into a register instead of memory will be much more “efficient.” Additionally, in a larger context, we could imagine that the compiler completely removes the representation of a_stack_cpp and just inlines the value 6 or 5 whatever is appropriate.
Again, a_stack_cpp is giving a zero cost abstraction while a_ptr_cpp and a_java are giving us a low cost abstraction w.r.t. the number of instructions evaluated.
Meta template programming
The advantages of zero cost overheads really shine when combined with templates and meta programming techniques. By having templated classes, we are able to construct a single class which implements many basic features that we are able to reuse. For example, suppose that we had a LogNumber class such that we could have LogNumber<LinearNumber<float> > and LogNumber<LinearNumber<double> > which use the same same which class implementation with two different sizes of numbers. We could even extend this to have LogNumber<LogNumber<LinearNumber<float> > > which would allow for us to easily represent a number in a log log space without having to reimplemented our LogNumber class.
If we implemented this templated class in Java, then we would have that every template parameter would require a pointer and another class instance. This means that in the LogNumber<LogNumber<LinearNumber<Float> > > we would require that there are 4 class instances and thus would require 4 pointer indirection to actually reach the floating point value and consume 64 bytes of memory.
In C++, this templated class does not use a pointer indirection when using a template. This means that the size of LogNumber<LogNumber<LinearNumber<float> > > and LinearNumber<float> will be exactly the same size. Additionally, accessing the stored number will only take a single memory access instruction and can be placed on the stack or used inside an array as shown above.
Conclusion
Abstraction is a very important concept when writing larger programs. Having zero cost abstraction available means that we can have both performant programs while reducing the mental burden on the programmer. When programming in a language such as Java or Python, we have to make a choice between developing the most performant program in that language and having a clean and reusable abstraction.
We see the power of zero cost abstractions aggressively used inside libraries such as Eigen,Dlib and Tensorflow as these libraries care immensely about the computational and storage efficiency. Using C++’s template system, these libraries contain a single implementation for a generic routine which can be customized by switching out a few minor methods without losing any performance.
This is a post that I started writing shortly after the Democratic convention, as I started thinking that Trump was going to end up beating Clinton. Now that the “impossible” has happened (haha all those “old media” predicting <2% for Trump) I find myself publishing this post as an attempted reflection on how we got here.
So what went wrong and what can be learned from this year? I think that the first and easiest way to frame this year might be “old establishment” vs “random unknowns” where a large number of individuals decided that unknowns would be better than more of the same for themselves. These individuals IMO tend to view the status quo as getting themselves screwed over by some external force, such as technological progress, trade deals, banks or immigrants, and as such wanted some candidate that would end what ever entity was screwing them over. When this battle comes down to between HRC and the Orange, we have one candidate that was essentially saying that things are not so bad and that what happened with the financial meltdown and bailing out the banks had to happen, and the other simply channeling people’s anger towards an undeserving group of people (immigrants). In the end, speaking to one’s frustrations rather than trying to tell them they are “crazy” and they are better off then X years ago was the better strategy (who would have guessed).
While it is easy to forget where we came from in terms of the primaries, considering that I starting this posts months before it was posted, it is easy to recall the events of a few weeks ago.
First, when the Tangerine said that he might consider a third party run if he was not treated fairly by the Republicans, this was an extremely smart home in hindsight. This was basically his escape hatch from the party which would have allowed the Tangerine to prevent a successful presidential bid if it came to light that there was any foul play during the primary processes. As such, the Republican party was forced in to playing a fair game and thus as an outsider Tangerine was given a fair shot.
The flip side of this issue was Bernie, who said that he would not consider a third party run which basically meant that he gave license to the Democratic party to sabotage the primary processes against him without their being any consequences (such as directly losing in November as a result). This is something that we know happened given the wide array of emails that have been leaked. (1, 2) (In the last few weeks alone there have been countless wikileaks which have shown the additional details of how the
Simply looking at the Democratic primary, we had HRC with Clinton being one of the few name brands bigger than Lewinsky (sorry, bad joke… someone had to make it), and Bernie, a politician who many (at least on the west coast) have never heard about before. The massive HRC name brand politician then proceeded to lose 22 primaries. Additionally, winning the primaries that she did required that she conspired with major media providers and spend years specifically maneuvering to control the Democratic party through DWS becoming the party head (her campaign manager in 2008) and getting countless super delegates to pre-signup with her campaign. When in it came to fund raising, Bernie was consistently out raising HRC and he was doing it using a larger pool of donors making smaller contributions which IMO indicates a campaign which was better in touch with the actual voters. We see a similar parallel when comparing the sizes of HRC and Bernie rallies.
In directly comparing Clinton to Tangerine and Bernie, we have HRC who continued to “evolve” her position to try and always attract the most voters while Bernie and Trump both took a position and keep pushing a core message. The fact that Tangerine keep changing exactly what he said on specific policy issues didn’t change the core message which was simple enough that it easily resonated with his core voting base.
TL;DR: If you fix your primary such that you ignore the “public poll” that you are conducing, the candidate that you get out is going to be weaker then they should be in the general election.
Some additional comments:
While the mainstream media is likely going to frame this as “America wasn’t ready for a woman president,” I don’t think that was the issue. Instead, Clinton was a weak candidate which to many Americans symbolized the failures of government that they can’t stand
The fact that “the most qualified Woman/person ever” just lost to the biggest “joke” we are unlikely to see another “Woman from a major political party” within the next 20 years. The only chance that the next woman has of getting a nomination is that she wins on a populace surge, the party insiders of the Republicans and Democrats are going to be unwilling to risk it
At some level the country has just “approved” the Tangerine’s personal views on race and women (given that this election wasn’t won on policy)
Once Clinton pivoted to the general, talks of policy basically stopped. Instead she started using personal attacks (forcing all those meaningless leaks about personal qualities). Instead of Bernie had been in the general, he would have keep the message focused on policy, people would have been able to more easily recognize that Tangerine had no real policy and would be unable to deliver.
If you want to have a chance of winning against Tangerine in 4 years, you are going to have to defeat him on the fact that he has bad policies or the poor job that he has done. More personal attacks are not going to work and is a dumb position to take and isn’t going to resonate well with younger generations.
The Tangerine tape scandal made no sense. (Again this isn’t a policy issue attack but a personal attack.) Some have said that this was a “waking up call” to women that were supporting Tangerine, I don’t think that actually holds that much weight. Lets suppose for a moment that Tangerine had “much better” policies then HRC w.r.t. women’s issues and this tape still came out, the conversation would have been: “So he said these things, but he is still much better for me as a woman.” America’s history of presidents has been a string of questionable views on women and marriages etc, one more shouldn’t really be a surprise to anyone regardless of how many times the media plays it. Most people will never directly interact with the president, “we” (or at least I), do not care if the person who wins the presidency is likable or has done some questionable things in the past, all that “we” care about is whether or not their policies are going to be good for “us.”
With the election a few days away, I found myself recently looking at the state of voting in America and contemplating that there is still no online-based voting system in place. The main arguments against online voting or digital-based voting has been that it would be hard to verify and would require a computer security expert to identify if something has been tampered with.
Now to create a system that is “provably incorruptible” would be very difficult and impracticable to expect average poll workers to verify the correctness of such a system, however, there is probably a widely unexplored range of systems that are better than our current system but still have some easy to verify properties. In this post, I attempt to create a voting system which no worse then our current voting system with respect to voter fraud and ensuring the votes are counted.
First, let’s consider the state of our current voting system, specifically the voting-by-mail system. Step 1 is to go online and register your address along with some identifying voter information. At a later point in time, the state will mail a ballot to your address which contains a “voting key” which maps various voting positions (who you would like for some office or position on a proposition) to some number \([1, 200]\). To vote, you bubble in your corresponding chosen numbers, wrap your ballot in more paper called a “secrecy sleeve,” put this in another envelope and mail it to the ballot counting location. Presumably, once your ballot arrives, someone will check the identifying information on the mailing envelope to prevent duplication and then pass the ballot and secrecy sleeve to someone else who is just going to count the votes. This two-level operation would prevent people from knowing who you voted for, assuming that the first poll works don’t look at the ballot inside the secrecy sleeve. In terms of ensuring that your vote is counted, we have to then trust the second poll worker to count the votes correctly. We might use more than one person for this second part to prevent errors etc.
Now in making a new system, we have to consider what possible vulnerabilities exist in the current system, as those could still be allowed in the new system:
Trusting the United states postal services (USPS) to properly deliver mail — If your ballot never makes it back to the polling place, then it will essentially be lost (there might be some ways to identify that it is lost, but still no real/easy recourse for ensuring that it gets counted)
The USPS needs to get you your ballot to you in the first place — If the ballot was sent to the wrong address, it is possible that someone fills in the ballot in your name, forges your signature, and then mails it back in
People are trusted to bubble in their choice correctly — Eg, they are at least able to understand that given some “number” on a “ballot key,” they are supposed to transfer that number correctly to the ballot itself
A malicious poll worker could prevent a vote from getting counted that they didn’t agree with — Given that your vote is easily identifiable on the ballot, it is trivial for someone to reject all ballots which have bubbled in number 10 (ideally, there are two or more people to double check that this does not happen)
Given this set of vulnerabilities in our current system, lets now try to design a better system that allows for internet voting:
Our first steps would be very similar to the current voting system, where someone goes online and registers with their mailing address. The state would then mail out a “ballot key” to the provided address. The reason that we would still require that something is mailed out is that there is currently no good way to identify a citizen online in a secure way, however, like the current vote-by-mail system, it is acceptable to trust the USPS as a “broker of identities.” Now our vote by internet ballot key will be a bit different from existing ballots where each vote is represented by \([1, 200]\) and instead have a number in \([0, 2^{256}]\), additionally, instead of having a single number (say 10) represent a position on the ballot, each voter would be given a unique number for each position on the ballot. (A sample ballot is at the end of this post) We can then use a simple website to collect the keys which represent a person’s choice. Given that each user has different codes generated for their ballot, we can use untrusted channels to communicate these codes to the vote-counting authority. Additionally, we do not have to worry about “suppressing” the vote that a poll worker disagrees with since the intermediate communication mechanisms don’t even know which vote was cast. All they know is that they are responsible for is communicating some number to the voting authority. Even if voter’s computer was infected with a computer virus, it would be unable to change your vote since it only knows the key that was entered representing your choice, while the other keys would only be present on the paper ballot key that was mailed to your address.
Some properties of this system:
We are still trusting the USPS to properly identify people and communicate information with them securely. (Same as before)
Submitting a vote for someone else still depends on your receiving or intercepting their ballot and “forging” a signature (Same as before)
The intermediaries do not know your vote (better than before) — Now your vote is a number that is specific to you, so the only people who will know the vote are the person who generated the “voting key” and whoever has the voting key
The intermediaries can not suppress your vote based on who you voted for — They do not who you voted for, so it can not be suppressed based on this reason
Your vote can not be changed after the fact — Changing your vote would require that the malicious intermediary have your “voting key book,” which was printed by the state and mailed by the USPS (which is a trusted medium)
Your computer (now technically also an intermediary) can not change your vote even if it was infected with a virus — your computer does not know the alternate keys you were provided since they were printed and mailed, so it can not switch between them.
The number that you have to enter is a lot longer (worse) — Currently, you only enter some number \([1, 200]\), however, a 256 bit number is notably longer. Given how people are already used to entering 16 digit credit card numbers, this might not be such a big issue. We could even include checksums to limit erroneously entering something (bitcoin already uses a 32-bit checksum on all addresses)
Some might point out that one could set up false voting websites to try to confuse voters or perform a DOS attack on the voting website. First, with false websites, we could follow the trend of some banking websites where an image is displayed to ensure that you are on the correct website. However, we might make it some confirmation code that is sufficiently long that it would be difficult to counterfeit and easy to print on a “ballot key.” For the DOS attack, we already know how to build systems that can deal with DOS attacks. Additionally, if we have a confirmation code system that confirms that a vote has been recorded, then any mechanism which takes a voting key and returns the confirmation code is as good as any other. This means you could have voting via email or even text message, which are “more difficult” to perform a DOS attack against or allow for third-party websites to spring up to collect votes as they would have to be still backed by the state vote recording authority.
Sample theoretical ballot key:
Politician
Office
key
Confirmation code
T Sandwich
President
NMosFJizjPgUV2BKEhGE rjvUZzKZVAFCyqPy7w3t
FuT8VDz3z
Giant D
President
Tru4oZn9y3RMnxAsb7g 5Gqs7Fu13FX4ExaQSer6y
bFcCf4MJA
None of the above
President
LaGeinvoBUduEbovp5z JDQJ6DQEdgSqZWgXzArhi
xjzEahMdi
(These politician names are based on this current season of south park.)
TL;DR: Online voting where you are still mailed your ballot via USPS, and your ballot contains keys that we consider “secure,” and you only submit one key that corresponds to your vote.
Update / additional background info / other posts on this topic:
While the mathematical concepts in these schemes are sound, it would be difficult to convince the public at large. In these cases, people would have to just generally trust that someone has done the correct thing with designing the voting systems. From an academic point of view, if these systems are implemented correctly, there wouldn’t even be a need for there to be vote checkers since they would “have to be correct.”
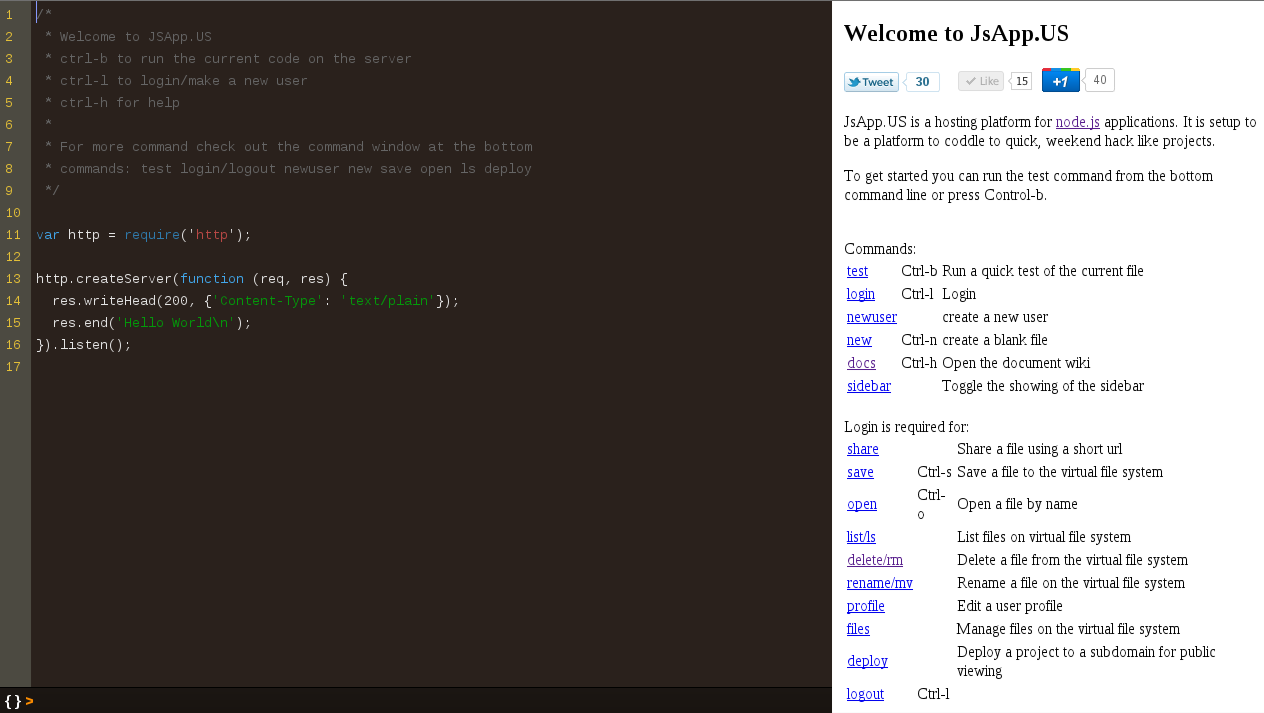
This post is a few weeks late, however JSApp.us has been shutdown. At the time that JSapp was first released, it was the first open node.js hosting platform. It featured an easy to use web based code editor (which was extremely useful at the time as developing node.js on windows was fairly difficult and required compiling code yourself). The system also provided CNAME support as well as subdomains for quickly developing demonstrating applications. There was even a command line client which allowed for quick deployments from the command line and uploading and downloading files from ones file system.
At last, JSApp’s time has come to an end. It has seen no major updates since 2011 (source) and the state of developing Node.js applications has moved on with new API’s (that were not supported by JSAPP) as well as new compile to JavaScript languages (which were also unsupported by JSApp).
Given the abundance of alternate Node.js hosting options and the age of the system, it seems that essentially all users have already migrated off the platform, so this change is unlikely to been disruptive. The source will remain available on github if anyone interested in some of the internals, however given how dated the system is, I am assuming that there are better solutions today for nearly all aspects of the system.
(This work and post were originally from early 2015, some aspects may still be useful, eg the kernel patch for the lower end motherboards)
Recently Intel has been selling their a version of their Xeon Phi coprocessor under a promotional deal at 90% off. This means that one can get a device with 8GB of ram (on the coprocessor) and 228 hardware threads (57 physical cores, and each with 4 hyper-threads) at a reasonable price of ~$200.
When I first purchased the Phi, I was planning to put it into somewhat of an old desktop system that I had lying around, however the motherboard did not support the major requirement of “Above 4G decoding” on the PCI bus. 4G decoding deals with how the system allocates the memory resources on items on the PCI bus. With the Intel Phi, unlike consumer level GPUs it will present all 8G as a memory mapped region to the host computer. (more about 4G decoding) Based off some research on this obscured feature, it appeared that most “modern” motherboard have some support for this feature. I decided to get an Asus h97m-plus which is fairly cheap, and fit the computer tower that I already had on hand. While this motherboard does list the above 4G decoding in its bios and manual, I am not actually sure if this feature has been properly tested, as unlike Asus higher end motherboards, there was no mention of this mother board specifically working with the above 4G decoding. Based off examining the early booting sequence it appeared that the Linux kernel was attempt to find alignment positions for PCI devices which were equal in size to the requested memory region (8GB in this case) or depends on the BIOS to perform the PCI allocation before booting. For the higher end motherboards which the Intel Phi was known to work with, it appears that the “more powerful BIOSes” were allocating memory for the Phi, but in the case of this lower end motherboard, the BIOS was unable to deal with a request to allocate 8GB of memory and thus falling back onto the kernel to perform allocations. Following this observation, I made a small kernel patch (here) which changes requests for alignment larger than the maximal size to be simply aligned at the maximal supported size. With the components in this computer it appears that even with this change the Intel Phi gets aligned to a 4GB boundary and is able to still function correctly.
The next challenge once the Phi was communicating with the computer was to prevent the chip from overheating. The discounted versions of the Phi did not include any fans as it was designed for use in server environments. Additionally being a 300+W accelerator, the system is capable of generating a lot of heat. As such, many “typical” fan solutions that I tried failed to keep the chip cool for longer than a few minutes. I eventually landed on the high-powered tornado fan which can move over 80 cubic inches of air a minute. I ended up having to zip tie this over one end of the chip to ensure that there was enough directed airflow to keep it functional. (warning to future users: This fan actually does sound like a tornado, constantly).
Having the entire system functional for over a year now, I have managed to use the Phi for a handful of computations. While there is decent opportunity in improved performance, this chip really requires that you design customized software for it specifically. This is especially true given that Intel Phi is less popular than graphics cards with Cuda, where many mathematical tools and frameworks already have customized backend targeting Cuda requiring limited effort on the user’s part. While this chip has a nice promise of being able to execute normal x86 instructions, this seems to be of fairly limited use since the only compiler that will target the chip and use its specialized vector instructions is Intel’s own compiler (similar in nature to Cuda). This makes it fairly difficult to natively run any non trivial programs on this chip as any external libraries require their own porting effort. (As an accelerator which accelerates embedded methods similar to Cuda this chip works fine, just if you are trying to run a program without the hosts involvement.)
Here is an interesting idea that I had recently, this is just a high level concept about how it would work, there are no proofs for error bounds or quality, in fact there would be a handful of orderings of sets which would product terrible results.
To accurately compute the \(n^{th}\) percentile value of a given set of values, one ends up having to sort the values which if they are not integers, can take \(O(n \log n)\) time. However, then getting value itself is trivial since it is simply going to the correct place in the sorted values. I am thinking that one should be able to compute an estimate for the \(n^{th}\) value for a randomly ordered set of elements in \(O(n)\) time.
First the basic idea, imagine that you have a set of elements \(X = \{ x_i \}\). Then if we had this set sorted \(S\), then finding the \(n^{th} (0 \le n \le 1)\) percentile out of \(X\) would simply become \(s_{n * |S|}\). This implies that we have \(n * |S|\) elements less than \(s_{n *|S|}\) and \(|S|*(1 – n)\) elements greater. From this point we can imagine constructing two sets, \(\alpha = \{ x \in X : x < s_{n * |S| } \}, \beta = \{ x \in X : x > s_{n * |S|} \}\) which represent the elements greater and less then the \(n^{th}\) value. This also means that \(\frac{|\alpha|}{|\alpha| + |\beta|} \approx n\). Now using this concept for \(\alpha\) and \(\beta\), we can attempt to construct these sets while iterating through \(X\) by having a current estimate for the value \(s\), and then tracking the elements current in each set. This essentially becomes if \(\frac{|\alpha|}{|\alpha| + |\beta|} > n + \epsilon\) then take the current value of \(s\) and insert it into \(\beta\), then take the largest element out of \(\alpha\) and set it equal to \(s\). In the case of \(\frac{|\alpha|}{|\alpha| + |\beta|} < n – \epsilon\) we simply do the reverse by inserting the current value of \(s\) into \(\alpha\), and then removing the smallest value from \(\beta\) and setting it equal to \(s\).
Now the problem has been reduce to splitting \(X\) into two different sets and keeping them sorted somehow to be able to get and remove the largest/smallest elements. However, this would give an exact answer to finding the \(n^{th}\) percentile. Now given that we want to find an estimate, we can imagine capping the size of these sets to \(k\), where \(k\) is a small number such as \(2\). Then instead of tracking the elements themselves, we are simply counting the number of elements that are greater or less than the current \(s\) value. Additionally, we have the sets tracking the \(k\) elements that are largest but still less then \(s\), and the smallest but greater then \(s\). As we iterate through the set, we can track the \(k\) values in \(\alpha, \beta\) and the size of \(\alpha, \beta\) accordingly, and when we want to change the value of \(s\) to keep \(\frac{|\alpha|}{|\alpha| + |\beta|} \approx n\), then we just take the new value from \(\alpha\) or \(\beta\) respectively and update the cardinality of each set.
An additional extension to this algorithm could be for an \(n \approx .999\) then the size of \(\beta\) would only be \(\frac{1}{1000}\) the size of the original data set. Keeping track of largest \(.001\) of the data set would not be linear in the side of the data set, however it could take out a considerable chunk of computation depending on how large or small the value of \(n\) is.
This last summer I spent a considerable amount of time refactoring i-lang. Since I started implementing this programming language in early 2012, it had accumulated quite a bit of cruft, and it was difficult to continue moving forward.
Refactoring type system
One of the first internal improvements that was made was to overhaul the internal type system. Before, the type system was simply passing around a boost::any. However, this became trouble some as all parts of the code would have to know about each type so that it could cast it locally. In many places the code began to look like:
The real beauty of this type system can be seen when using the foreign function interface, where the value of arguments can be “injected” into local variables. This means that a function can be written as:
// The arguments are casted to the type of the local variable
// in the case that a cast fails, an exception will be raised
// which is the logical equivalent to calling a function with
// the wrong type signature
// ... (body of function)
return valueMaker("hello world");
}
Changes in the type system at the language level
Before this refactor, types in i-lang were defined in a global table of identifiers called variable modifiers. A variable could have more than one modifier attached to it, and each modifier is used to check the value being set to a variable. What this roughly translates to would be something like:
define_type("Unsigned", {|a|
// check if the value being set, which is passed as argument a, is greater or equal to 0
return a >= 0;
});
// use this type like
Unsigned Int b = 5; // both Int and Unsigned are called to validate the value of '5' is the correct type.
Looking at this implementation of a type system, it does not seem that bad when compared to other programming languages. As displayed here it is missing the concept of a namespace or import scope, but otherwise it is fundamentally a type system where types are given names and then later used to reference that type. However, this concept of a type having a name fundamentally goes against i-lang’s concept of names only being used as place holders for values, vs having an explicit places in the language. (eg: class required_name_of_class {} vs name_bound_for_use_later = class {}). This lead me to question what does a type system fundamentally do. In lower level languages such as C/C++ a type system provides information about the space required for an object, however in a higher level language such as python (which i-lang is more similar to on this point) values are just fixed sizes and then pointers to larger dynamically sized objects when required. Type system also provided casting between primitive types, such as a 4 byte integer casted to a floating point. This on its own isn’t that interesting as there are limited number of primitive types and similar operations can be accomplished with code like `1 * 1.0` or `Math.floor(1.2)` for casting. Finally, type systems provide a way to identify the type of some value, which can be further used by a language to provided features such as pattern matching when calling a function. Now, choosing to focus on this last issue of a type system lead to i-lang concept of a type system, which is that a type is simply a function which can identify if a value is a member of a given type.
The idea of using just a function to identify a type can sound a little strange at first, however, after playing with it some, the idea itself can be seen to be quite powerful. Here is a quick example of using this type system to implement pattern matching on the value passed to a function.
// This is a function which returns a function that compares the value
// the returned function gets with the value the first function was called with.
GreaterThan = {|a|
return {|b|
return b > a;
};
};
LessThan = {|a|
return {|b|
return b < a;
};
};
EqualTo = {|a|
return {|b|
return b == a;
};
};
Example_function = {|GreaterThan(5) a|
return "The value you called with is greater than 5";
} + {|LessThan(5) a|
return "Then value you called with is less than 5";
} + {|EqualTo(5) a|
return "The value you called with is equal to 5";
} + {
return "The value you called with didn't compare well with 5, must not have been a number";
};
Int GreaterThan(0) LessThan(10) int_between_zero_and_ten = 5;
In the Example_function, we are combining 4 different functions, each with different type signatures. Additionally, we are creating types on the fly by calling the GreaterThan/LessThan/EqualTo functions which are using annoymious functions and closures. This method also allows for classes to have a place in the type system. We can now easily create special member of a class to check if a value passed is an instance or interface of the class type.
sortable = class {
Function compare = {};
};
// check that the array members all implement a compare function and are an instance of a class
sort = {|Array(sortable.interface) items|
// ...
};
Refactoring Objects and Class to appear like functions
Before, i-lang use syntax similar to Python or JavaScript dicts/objects when constructing a class or object. This meant that these items looked like:
class {
Function_to_check_type type_name: value_of_type,
Another_type another_name: another_value,
no_type_on_this: value
}
However, in ilang, except when prefixed with `object` or `class` the use of `{}` means that it is a function. (eg: a = { Print("hello world"); };) Additionally, colons are not used anywhere else in the language, which made me question why was this case such a special one. This lead me to ask why not use equal signs and semicolons like everywhere else, meaning that defining a class would appear as:
Furthermore, is there any reason to exclude loops and if statements when constructing a class? Allowing control flow when the class definition is constructed makes this act identical to a function.
a = true;
class {
if(a) {
b = 5;
} else {
b = 6;
}
}
Final thoughts
By starting by cleaning up the internals of i-lang, it allowed me to take another look at the language and determine why certain choices were made at first. Bootstrapping a new programming language takes a considerable amount of effort, and could easily lead someone to defining something like print a function (as python recently changed away from in version 3). In my case, I was creating special mechanisms for constructing class/objects and defining types for variables largely because the type system, scopes, and function internal interfaces were all poorly designed in the first iteration of the language. Now that the internals have been cleaned up, it makes it easier to see that these changes are wins for the language. Now, I doubt that I would have been able to come up with these changes right off the bat with the first implementation, as it was only through the pain of the first implementation for which the need for these changes became apparent.
This is the first week back at school, which means that the speed of development on ilang will begin to fluxuate again. Over this last break, and the final parts of last semester, I was able to clean up a bunch of features with the ilang programming language.
When I originally set out to create this new language, I was mostly thinking about how the syntax would be different and the specific features that I would want in the language to make it worthwhile of being created. However, what I failed to thinking about was what really make a programming language useful today is the fact that there are an absurd amount of libraries already programmed, debugged and available for download for any successful language. As a result of this realization, I have been working on trying to get useful libraries written for the language. However in trying to work with the language, I have a few beliefs that I am trying to stick with, but I am not so such how well it will work out.
The first belief, is that there should be no need to pause or have any sort of timer system, this is because I feel as if the language should attempt to run as fast as possible and focus on processing data. However when writing testing frameworks to automatically check if the language is working, it has become apparent that it would be useful to have some timer system. ** I still haven’t written in the timer system so this is still somewhat of an issue of internal debate.
Along with the timers, there is the problem of getting data efficiently in and out of the programming language. One of the concepts that I have for the future with this language is that the system will be able to distribute the computations between a large number of computers, this means that it is not particularly natural for the system to have access to features of the local computer, such as the file-system or the standard in/out. I am thinking that for the time being that the system could be designed to have access to the standard input and part of the file-system, however when the system becomes networked across a lot of computers, there could possibly be a way to specify where the standard input/output should go along with where the file-system has access to. The other alternate that I am working on, is using the concept of just having the http server be the way to input data, however I expect that it will become cumbersome quickly to input large data files. A possible compromise is to use the parameters to support some way to map specific files or folders to names that can be access from inside the program.
When considering the libraries that have already been included, there is still a lot of space for development. The modification library is still lacking too many features to be really usable. Along with the modification, the database library, still lacks the ability to save arrays into the database. The complication with arrays is trying to figure out an efficient way to store the data without causing a significant slow down. My plan for arrays in the database, was that they would be “smaller” then objects in the database, as objects when stored in the database do not have any limiting factors for the number of elements. However with arrays, I plan to try to have the system load all the data into memory when reading an array from the database. However the current way that the system is designed, it does not allow for the elements, to be easily accessed under the hood. I am thinking that the system might try and store all the elements in their own container, however the problem with this is that there would be a large number of database queries when trying to read data out. And inserting in the middle of the array would require a large number of read and writes into the database. However, on the flip, if the system was using one database object to store all of the array elements, there would be a few read and writes, but the object would likely be come very large very quickly.
The current plan for future features, is to keep working on adding more libraries into the core system to be useful. This will mostly focus on processing and interpreting data. (Web server, http client, as well as methods to parse string such as regex, also expecting some form of CSV or sqlite reader for when working with data that has been downloaded). Along with supporting reading the data, I plan to attempt to include a wide range of machine learning and artificial intelligence libraries and tools. Hopefully, it will be easy enough to integrate their database systems with the ilang database. Once these components are in somewhat of a usable state, I should have some framework for which experiments with the code modification library can be conducted.
Random last thought:
I currently plan for the ilang system to have a formatting tool, much like golang does. The reason for this, is when working with the modification system, I plan to have the system completely regenerate a file using the system “print from code tree” feature. This should greatly simplify writing the code back to disk, when compared to other possible ideas such as trying to find where the code has been changed with corresponding lines and then try to recreate those changes on disk.